Our Data Transformation Process
The process of data transformation involves several key steps, which may vary based on your specific context and requirements. Plus, these workflows can be handled manually, automated or a combination of both. Here are the most common steps:

- Data Discovery and Interpretation
- Understand the types of data you currently have from different sources and determine what format it needs to be transformed into.
- Consider file extensions, but also look deeper into the actual data structure to avoid assumptions.
- Identify the target format for the transformed data.
- Pre-Translation Data Quality Check
- Before proceeding, verify the quality of your source data.
- Detect missing or corrupt values that could cause issues during subsequent transformation steps.
- Data Mapping and Code Development
- Map the source data fields to their corresponding fields in the target format.
- Use tools or develop scripts to perform the necessary transformations.
- Code Execution and Validation
- Execute the transformation code or processes (e.g., aggregations, calculations, filtering) to align the data with the desired format.
- Validate the transformed data and data model to ensure correctness and consistency.
- Address any discrepancies or errors that arise during this step.
- Data Review and Documentation
- Review the transformed data to confirm its accuracy and completeness.
- Document the transformation process, including details about applied rules, mappings, and any adjustments made.
- Maintain clear records for future reference and troubleshooting.
Keep in mind that not all your data will require transformation, on rare occasions, your source data can be used as is.
Types of Data Transformation
Various data transformation methods are employed to prepare raw data for data wrangling, analysis and model training. It’s important to note that not all techniques are universally applicable, and sometimes you may combine multiple methods.
Top transformation techniques:
- Cleaning and Filtering: Identify inconsistencies, errors, and missing values in the data set. Remove irrelevant or duplicate data, and handle missing values appropriately (e.g., by imputation or removal).
- Data Normalization: Scale numerical features to a common range (e.g., 0 to 1 or -1 to 1). This ensures consistent magnitudes across features, aiding machine learning models in accurate predictions.
- Data Validation: Ensure data correctness by verifying data types, formats, accuracy, consistency, and uniqueness. It’s a crucial step to prevent flawed results in data analysis and machine learning.
- Format Conversion: Change the representation of data from one format to another (e.g., encoding conversion, file format conversion, or data serialization). This brings compatibility across systems and applications, facilitating seamless data exchange and efficient processing.
- Power Transform: Use mathematical techniques to stabilize variance and make data distributions more Gaussian-like, which is essential for improving the performance of machine learning algorithms. They include methods like the Box-Cox transform and the Yeo-Johnson transform.
- Attribute Construction: Create new features by combining or transforming existing ones. For example, calculating ratios, aggregating data, or deriving time-based features.
- Derivation: Similar to attribute construction, here you create new variables or columns based on existing data through calculations or transformations.
- Encoding Categorical Variables: Convert categorical variables (like gender or product categories) into numerical representations (one-hot encoding, label encoding, etc.). This is sometimes referred to as vectorization.
- Log Transformation: Apply logarithmic transformation to skewed data distributions to make them more symmetric.
- Smoothing: Reduce noise in time series data by applying moving averages or exponential smoothing.
- Aggregation: Summarize data at a higher level (e.g., daily sales aggregated to monthly sales).
- Discretization: Convert continuous variables into discrete bins (e.g., age groups, income brackets).
- Feature Scaling: Standardize features to have zero mean and unit variance (e.g., using Z-score normalization).
- Feature Engineering: Create new features based on domain knowledge or insights from the data.
- Key Structuring: Map specific meanings to generic identifiers for use as unique keys.
- Data Enrichment: Enhance the dataset with additional information from external sources to provide more context or detail for analysis.
- Simple Manipulations: Enhance search performance by sorting, ordering and indexing data. Pivoting converts column values into rows or vice versa.
Transformations in ETL and ELT
First, let’s define the letters ETL:
- Extract refers to the process of pulling data from a source such as an SQL or NoSQL database, an XML file or a cloud platform.
- Transform refers to the process of converting the format or structure of a data set to match that of a target system.
- Load refers to the process of placing a data set into a target system.
Now we’ll describe how data transformation can occur at different points in your data pipeline depending on whether you have on-site or cloud-based storage and the size of your data sets.
ETL: On-Premises Storage & Small Data Sets
If you have traditional on-premises data storage and you have small data sets which require complex transformations, you’d follow an extract, transform, load (ETL) process, where transformation happens during the middle “transform” step.
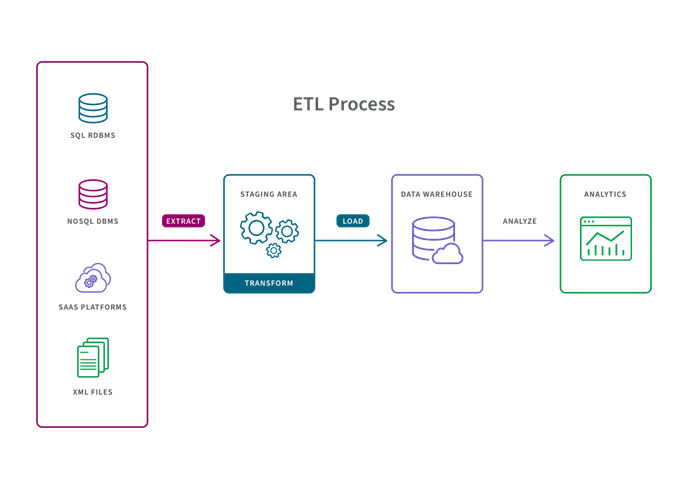
- A predetermined subset of data is extracted from the data source.
- Data is transformed in a staging area in some way such as data mapping, applying concatenations or calculations. Transforming the data before it is loaded is necessary to deal with the constraints of traditional data warehouses.
- Data is loaded into the target data warehouse system and is ready to be analyzed by BI or data analytics tools.
Key advantages of ETL process:
- Stability and Speed: ETL ensures stable and faster data analysis for specific use cases. Since the data is already structured and transformed, users can work efficiently.
- Compliance Ease: ETL tools simplify compliance with standards like GDPR, HIPAA, and CCPA. Users can exclude sensitive data before loading it into the target system.
ELT: Cloud Storage & Larger Data Sets
If you have modern cloud-based storage and larger data sets (and/or if timeliness is important), you can bypass ETL. Instead, you use a process called extract, load, and transform (ELT), and transform data in the target system.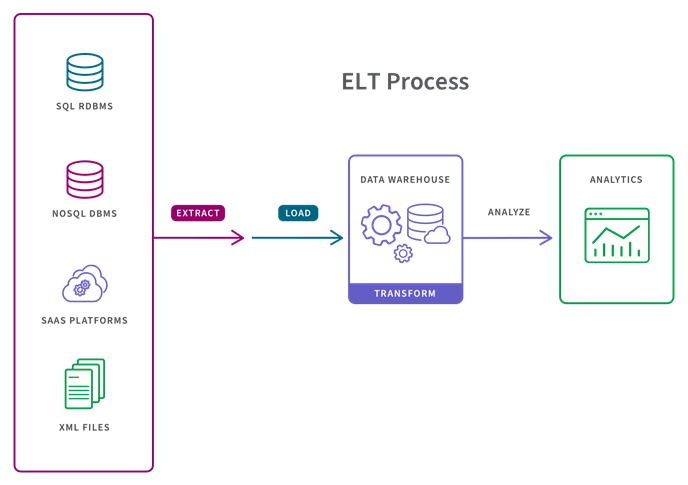
- All data is extracted from the data sources.
- All data is immediately loaded into the target system (data warehousing or a data mart or data lake). This can include raw, semi-structured and structured data types.
- Data is transformed in the target system and is ready to be analyzed by BI tools or data analytics tools.
Key advantages of ELT process:
- Real-Time, Flexible Data Analysis: ELT allows users to explore the entire data set, including real-time data, in any direction without waiting for IT to extract, transform, and load additional data.
- Cost Efficiency and Low Maintenance: ELT benefits from cloud-based platforms with lower costs and various storage and processing options. Additionally, the process requires minimal maintenance since data is always available, and transformations are typically automated and cloud-based.
Examples
Here are examples of how you might apply 3 types of data transformation in your overall data management process.
Data Aggregation. You may want to summarize information at a higher level, such as:
- Calculating your average monthly sales from daily sales data.
- Summarizing website traffic by week instead of daily records.
- Aggregating customer purchase history to analyze overall trends.
Converting Non-Numeric Features into Numeric. Your machine learning algorithm may require numeric input. If you have non-numeric features (e.g., categorical variables), you can transform them into a suitable numeric representation. For instance, converting text labels into one-hot encoded vectors allows you to perform matrix operations on them.
Resizing Inputs to a Fixed Size. Certain models, such as linear regression or feed-forward neural networks, expect a fixed number of input nodes. If your input data varies in size (e.g., images with different dimensions), you can resize or crop them to a consistent size before feeding them into the model.
Benefits of Data Transformation
Data transformation offers many benefits that enhance the effectiveness of your data analysis and decision-making. Here are the 4 key benefits:
Improved Data Quality
- Transforming data ensures that it is properly formatted, validated, and organized.
- High-quality data protects applications from issues like null values, unexpected duplicates, incorrect indexing, and incompatible formats.
Enhanced Accessibility
- Properly transformed data becomes more accessible to both computers and end-users.
- It facilitates compatibility between different applications, systems, and types of data.
Efficient Decision-Making
- By making data usable for analysis and visualization, transformation supports business intelligence and data-driven decision-making.
- Until raw data is transformed, its true value cannot be fully leveraged.
Time and Cost Savings
- Automating transformation processes reduces manual effort and saves time.
- Companies can streamline data entry and analysis, leading to operational efficiency and cost reduction.
Challenges
A robust data transformation process is complicated. Performing the techniques described above isn’t easy if you don’t have the right tools or full support of your organization. Here are some the key challenges you may face:
Growing Complexity
- As unstructured data (such as text and media) explodes, the complexity of required transformations skyrockets.
- Handling diverse, multi-structured data demands intricate logic and adaptability.
Ensuring Data Quality
- Generating clean, consistent data post-transformation is critical but tricky.
- Ensuring that transformed data meets quality standards (free from errors, duplicates, and inconsistencies) remains a challenge.
Performance Overheads
- Transforming big data strains infrastructure and computational resources.
- Heavy computational power is needed, which can slow down other programs or processes.
Securing Data
- During transformation, sensitive information may be exposed.
- Ensuring data security, especially when handling personally identifiable information (PII), is a constant challenge.
Tool Selection
- Choosing the right data transformation tools is crucial.
- Factors like cost, scalability, ease of use, and compatibility with existing systems impact tool selection.